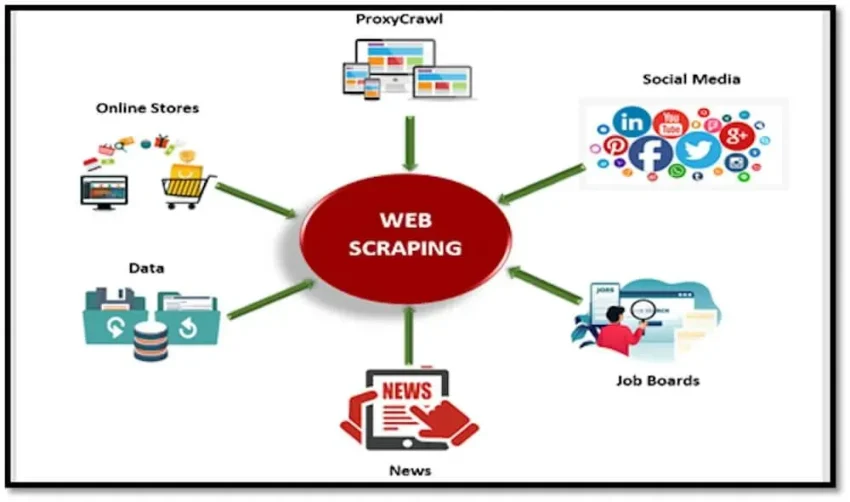
Web scraping techniques have revolutionized the way we gather and analyze data from the ever-expanding internet. With tools like Python web scraping libraries, including Beautiful Soup and Scrapy, users can effortlessly extract valuable insights from web pages. These techniques enable the automated collection of information ranging from product prices to real-time news updates, which can then be analyzed for various purposes. To ensure you are utilizing the most effective methods, it’s crucial to adopt web scraping best practices, which include respecting a site’s terms of service and employing efficient data extraction strategies. This tutorial will dive into the essentials of extracting data from websites while highlighting core programming concepts and real-world applications.
In the vast realm of data collection, the art of web data harvesting or website scraping stands out as a powerful method for researchers, developers, and analysts alike. This approach not only facilitates the extraction of important information from online platforms but also allows users to leverage frameworks and tools to simplify the process. Utilizing alternatives like HTML parsing libraries and automation scripts, one can efficiently capture articles, product information, or market trends without manual effort. By adhering to ethical standards and best practices in the industry, individuals can maximize their success in data retrieval while avoiding common pitfalls associated with online content scraping. Join us as we delve into the world of automated data extraction and its myriad of applications across various fields.
Introduction to Web Scraping Techniques
Web scraping techniques are essential for gathering information from various online sources. By utilizing programming languages like Python, you can automate the extraction process to gather data systematically. Web scraping allows you to collect insights from multiple web pages and compile them into structured formats for analysis.
To implement effective web scraping techniques, it is vital to understand the underlying HTML structure of the webpage you want to scrape. This understanding aids in locating the right elements, such as titles, paragraphs, and images, that contain the information you need. Knowing how to navigate through this structure is crucial for a successful web scraping operation.
Python Web Scraping: Getting Started
Python web scraping is one of the most popular methods for extracting data from websites. With libraries such as Beautiful Soup, you can easily parse HTML documents and retrieve the desired information. For beginners, Python provides a user-friendly syntax, making it accessible for anyone interested in data collection.
To get started with Python web scraping, you must install the necessary libraries. Beautiful Soup is particularly favored for its straightforward API. Once installed, you can leverage its capabilities to navigate the HTML tree structure, allowing you to locate specific tags and retrieve text, attributes, and media from web pages.
Beautiful Soup Tutorial: A Step-by-Step Guide
A Beautiful Soup tutorial guides you through the essential aspects of using this library for web scraping. It begins by explaining how to install Beautiful Soup and its dependencies, which typically include the requests library for fetching web content. The tutorial then walks through basic methods such as ‘find’ and ‘find_all’ to extract specific elements from a webpage.
As you progress in the tutorial, you’ll learn how to handle more complex scraping scenarios, such as dealing with dynamic content loaded via JavaScript. Understanding how to use CSS selectors alongside Beautiful Soup can greatly enhance your scraping capabilities, allowing you to retrieve exactly what you need from the web.
Using Scrapy for Advanced Web Scraping
Scrapy is another powerful tool for web scraping that is particularly suitable for larger projects. Unlike Beautiful Soup, which is mainly a parsing library, Scrapy is a complete web scraping framework designed for efficiency and scalability. It includes features such as handling requests, following links, and storing scraped data.
The benefits of using Scrapy include its ability to scrape multiple pages simultaneously, which greatly increases the speed of the data extraction process. This framework allows developers to create spider classes that define how a specific site should be scraped, providing a flexible and reusable architecture for web scraping tasks.
Extracting Data from Websites: Best Practices
When extracting data from websites, adhering to best practices is crucial for successful and ethical scraping. Always check a website’s ‘robots.txt’ file to understand the rules regarding scraping, and ensure that your actions comply with these guidelines. Observing legal and ethical standards not only protects you but also respects the website’s terms of service.
Additionally, implementing polite scraping techniques, such as adding delays between requests and limiting the number of requests per minute, can help minimize server load. By using these best practices, you can maintain a positive relationship with website owners while effectively extracting the data you need.
Common Challenges in Web Scraping and Solutions
Web scraping often encounters several challenges, including changing HTML structures and anti-scraping measures. Websites may alter their layouts, which can break your scraping code, necessitating regular updates to your scripts to adapt to new structures. Furthermore, some sites implement CAPTCHAs or request throttling to prevent automated access.
To tackle these challenges, it’s essential to build robust error handling in your scraping code. Implementing features such as retrying failed requests or adjusting scraping strategies dynamically can help you cope with changes. Additionally, using libraries like Selenium can aid in handling JavaScript-heavy sites and can navigate through CAPTCHA challenges more effectively.
Parsing HTML with Python: Techniques and Tips
Parsing HTML with Python is a critical aspect of web scraping, and there are several techniques you can employ to improve your efficiency. Along with Beautiful Soup, leveraging regular expressions can help you pinpoint specific data points within the HTML. Understanding Document Object Model (DOM) structures can also enhance your ability to extract the right information.
Tips for effective HTML parsing include using the right tools for your specific needs. For simple projects, Beautiful Soup or lxml may suffice, but for more complex applications, consider using Scrapy or Selenium. Also, always ensure your parsing logic is resilient against changes in HTML formatting to avoid frequent script breaks.
Storing Scraped Data Effectively
Once you have scraped data from a website, the next important step is storing it effectively. Choosing the right format for data storage depends on the intended use and analysis. Common formats include CSV, JSON, or databases like SQLite and MongoDB, each with its own advantages. CSV files are great for simple data structures, while JSON is beneficial for nested data.
When storing scraped data, it’s also important to consider data integrity and consistency. Implementing validation checks during data collection can help ensure that the information is accurate and stays aligned with the original sources. Prioritizing organized storage will make it easier to analyze or visualize your data later on.
Web Scraping Tools: Choosing the Right One for Your Project
The selection of web scraping tools is paramount to the success of your data extraction project. There are numerous tools available, each offering different features that cater to distinct requirements. For instance, while Beautiful Soup is excellent for simple parsing tasks, Scrapy is better for large-scale projects requiring comprehensive crawling capabilities.
When choosing the right tool, consider factors such as the complexity of the website, your experience level, and the specific data you need. Some tools come with built-in functionalities like browser automation, while others may require you to write more code to achieve similar results. Assessing your project’s needs against the capabilities of these tools can save you time and enhance your efficiencies.
Legal and Ethical Considerations in Web Scraping
Understanding the legal and ethical considerations in web scraping is crucial for any developer. Websites have different terms of service that govern data scraping, and it is important to comply with these to avoid legal repercussions. Familiarizing yourself with laws regarding copyright and data protection can help mitigate risks while scraping publicly available information.
Ethics in web scraping also encompasses respecting user privacy and the website’s operational limits. Practicing responsible scraping, such as limiting request rates and avoiding excessive downloads, helps maintain a positive environment for all web users and owners.
Frequently Asked Questions
What are the best practices for Python web scraping?
When engaging in Python web scraping, best practices include respecting the website’s robots.txt file, rate limiting your requests to avoid overwhelming the server, and using appropriate user-agent strings. Additionally, employing libraries such as Beautiful Soup or Scrapy can streamline the process of extracting data from websites while ensuring clarity and organization in your code.
How can I use Beautiful Soup for web scraping?
Beautiful Soup is an excellent tool for web scraping in Python. It allows you to parse HTML and navigate the parse tree easily. By using Beautiful Soup, you can extract data from websites with simple commands, such as finding elements by tag or class. An essential aspect is understanding the structure of the HTML document to accurately extract elements you need.
What is Scrapy web scraping and how does it work?
Scrapy is a powerful and popular web scraping framework for Python. It facilitates the extraction of data by allowing you to write spiders that crawl websites and extract information efficiently. Scrapy also manages requests, responses, and data storage, which makes it suitable for large-scale web scraping projects. Using Scrapy, you can build scalable crawlers quickly to gather data from multiple pages.
How do I start extracting data from websites using Python?
To start extracting data from websites using Python, you’ll want to set up your environment with libraries like requests for making HTTP requests and Beautiful Soup for parsing HTML content. Once you’ve gathered your target webpage’s content, you can utilize Beautiful Soup’s methods to identify and extract the desired data from the document.
What should I consider when scraping content from news websites?
When scraping content from news websites, it’s important to consider legal and ethical implications, such as copyright restrictions and terms of use. Additionally, ensure you structure your scraper to respect the load on the server by implementing rate limiting and checking the robots.txt file. This ensures your web scraping adheres to best practices and does not disrupt the website’s normal operations.
| Key Points |
|---|
| Do not directly access or scrape content from external websites like Reuters. |
| Focus on elements like title, main body, media, author, and publication date for effective scraping. |
| Use Python with libraries such as Beautiful Soup or Scrapy for web scraping tasks. |
| A basic Python example shows how to extract title and content using Beautiful Soup. |
Summary
Web scraping techniques encompass various methods for extracting data from websites. By utilizing tools like Python and libraries such as Beautiful Soup and Scrapy, you can efficiently gather information from webpages. This includes capturing crucial elements such as titles, content, author names, and publication dates, which are essential for understanding the context of the scraped data. Properly implementing these techniques allows you to automate the data collection process and unlock valuable insights from online resources.