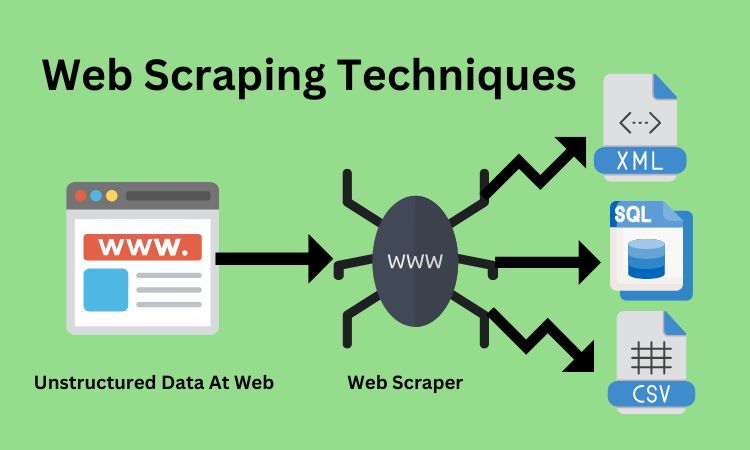
HTML content scraping techniques are essential for anyone looking to gather data from websites efficiently. With the right web scraping tools, users can extract valuable information such as articles, product details, and more, all from the vast expanse of the internet. This guide will help beginners to understand the fundamentals of HTML scraping and provide a comprehensive HTML scraping tutorial that covers various scraping techniques. Whether you’re interested in SEO content scraping for boosting your search rankings or simply want to automate data extraction from HTML pages, mastering these techniques will set you on the right path. Join us as we explore the world of scraping and equip yourself with the skills needed for effective data gathering!
Delving into web scraping, or the practice of extracting data from websites, opens up a realm of possibilities for data enthusiasts and professionals alike. By utilizing effective HTML content extraction methods, individuals can harvest crucial information that can enhance their business strategies or enrich research projects. This exploration of reliable scraping techniques for beginners not only simplifies the daunting task of data collection but also empowers users with key insights drawn from vast online resources. As we navigate through various web scraping frameworks and tools, you will discover how easy it can be to automate the data acquisition process. Prepare to enhance your understanding of digital data management by learning about the innovative processes behind efficient content scraping!
Understanding HTML Content Scraping
HTML content scraping refers to the process of extracting data from websites using specific tools and programming techniques. This method is widely used in fields such as data analysis, market research, and digital marketing to acquire valuable information from online sources. The fundamental principle behind this technique is to identify the elements within the HTML structure of a web page and extract the desired data efficiently, often using automated scripts.
To begin, you should familiarize yourself with various web scraping tools available in the market, such as Beautiful Soup, Scrapy, and Selenium. Each of these tools has its unique advantages depending on your specific needs. Some are more suited for beginners looking for straightforward HTML scraping tutorials, while others cater to advanced users needing sophisticated scraping capabilities. Understanding these tools will help improve your data extraction from HTML, enabling you to gather and analyze vast datasets for any analytical task.
Essential Web Scraping Tools for Beginners
When diving into the world of web scraping, selecting the right tools is crucial for your success. Tools like Beautiful Soup and Scrapy are popular among beginners due to their user-friendly interfaces and comprehensive documentation. Beautiful Soup provides an easy way to navigate through the parse tree of HTML and extract data efficiently, while Scrapy offers a robust framework for building your web scraping projects.
Another essential tool is Selenium, which is particularly useful for scraping dynamic content generated by JavaScript. With its capability to mimic browser behaviors, Selenium allows users to extract data that traditional HTML scraping might miss. Understanding these different web scraping tools will foster your development and enable you to tackle projects of varying complexity in data extraction.
Effective HTML Scraping Techniques
Mastering effective HTML scraping techniques can significantly enhance your data collection efforts. A strategic approach includes understanding the Document Object Model (DOM) of a webpage, which allows you to pinpoint exactly where the information you want resides within the HTML structure. This understanding aids in employing the right CSS selectors or XPath queries that precisely target the elements needed for extraction. Additionally, leveraging tools from the previous sections will ensure that your scraping techniques are efficient and reliable.
Moreover, incorporating best practices into your scraping techniques is vital for long-term success. For instance, respecting the ethical considerations of scraping—such as the website’s ‘robots.txt’ file and the terms of service—can save you from potential legal setbacks. Furthermore, implementing error handling and managing your request rate will help reduce the likelihood of being blocked by the websites you are scraping, leading to more consistent data extraction outcomes.
SEO Content Scraping: Best Practices
SEO content scraping involves collecting content from various online sources for the purpose of enhancing your website’s search engine ranking through content aggregation. However, it’s essential to ensure that your practices align with ethical SEO guidelines. This means that while you can scrape data for ideas, it’s imperative to rephrase, analyze, and add your unique value to the content before publishing it on your site.
Additionally, utilizing scraping tools effectively can aid in discovering trending keywords and topics that are currently resonating with your target audience. Tools like Moz or SEMrush can complement your scraping approach by providing insights on keyword competition and search volume, enabling you to craft better, SEO-optimized content that draws traffic.
Data Extraction from HTML: A Step-by-Step Guide
Data extraction from HTML can be broken down into several methodical steps to ensure effective retrieval of information. Start by identifying the target HTML documents you wish to scrape, followed by analyzing their structure to determine where the data of interest resides. Utilizing a well-structured approach, parse the HTML using powerful tools like Beautiful Soup, which will efficiently guide you in navigating the nested elements within the structure.
Once the parsing is done, the next step involves implementing the extraction logic to pull specific information from the identified HTML tags. This may include scraping text, links, or even images relevant to your project. Careful attention during this phase will ensure the data collected is useful and relevant, paving the way for effective analysis or integration into your database.
The Legal Side of Web Scraping
Understanding the legal implications of web scraping is crucial for anyone involved in data extraction. Different jurisdictions have various laws regarding data scraping, and it’s essential to familiarize yourself with them before engaging in scraping activities. Websites often have terms of service or a ‘robots.txt’ file that outlines what is permissible and what isn’t. Violating these terms can lead to legal challenges, and as a web scraper, we must navigate this landscape with caution.
To mitigate legal risks, it’s advisable to adopt ethical scraping practices that respect a website’s data and policies. This includes avoiding excessive requests that could disrupt a website’s operations and focusing on publicly available data. Ensuring compliance not only protects you legally but also fosters a more sustainable relationship with the online ecosystem you’re sourcing data from.
Building a Web Scraping Framework
Creating a web scraping framework involves establishing a structured methodology that can be reused across multiple scraping projects. A good framework should include modules for handling requests, parsing HTML, managing output data, and dealing with errors gracefully. By modularizing your code, you simplify the maintenance process and allow for easier updates or enhancements as needed.
Moreover, implementing a logging system within your framework can significantly assist in tracking the scraping process. This feature will help identify failures or issues that need addressing without disrupting your overall workflow. By building a robust web scraping framework, you not only streamline your current projects but also pave the way for future data extraction endeavors.
Common Challenges in HTML Scraping
HTML scraping is not without its challenges, and being aware of these can make a significant difference in your scraping projects. One common issue is dealing with dynamic content that loads asynchronously. Many modern websites utilize JavaScript frameworks that can prevent traditional scraping methods from retrieving the desired data. In such cases, tools like Selenium that can simulate user interactions may be necessary to access all data points.
Another challenge is ensuring the accuracy and consistency of the scraped data. Websites often change their layout and structure, which can break scraping scripts that were designed based on a specific HTML structure. Implementing regular checks and updates can alleviate this issue, but it requires ongoing maintenance efforts to keep scraping scripts functional and reliable.
The Future of Web Scraping in Data Science
As we move deeper into the era of big data and artificial intelligence, the importance of web scraping in data science continues to grow. The ability to extract and analyze information from diverse online sources provides businesses and researchers with insights that can drive decision-making processes. Web scraping will increasingly blend with AI technologies to automate data collection, further enhancing its relevance across industries.
Moreover, emerging technologies may soon provide even smarter scraping tools that can adapt to dynamic web layouts or circumvent common anti-scraping measures. As these tools evolve, they will unlock greater opportunities for data-driven insights, while also emphasizing the need for ethical considerations and compliance with legal standards.
Frequently Asked Questions
What are the best web scraping tools for HTML content scraping techniques?
Some of the best web scraping tools include Beautiful Soup, Scrapy, and Selenium. These tools help users extract data efficiently from HTML content by providing robust libraries and frameworks dedicated to scraping web pages.
Where can I find a comprehensive HTML scraping tutorial?
You can find a variety of comprehensive HTML scraping tutorials on websites like Medium, freeCodeCamp, and official documentation for web scraping libraries. These tutorials often cover essential scraping techniques for beginners, guiding them through the process of extracting data from HTML.
How can I efficiently perform data extraction from HTML using scraping techniques?
To efficiently perform data extraction from HTML, start by identifying the data elements you need, then use tools like Beautiful Soup or Puppeteer to parse the HTML. By applying CSS selectors or XPath, you can effectively navigate the HTML structure to retrieve the desired content.
What is SEO content scraping and how does it work?
SEO content scraping involves extracting information from websites to analyze competitors’ content or gather data for optimization strategies. By using HTML scraping techniques, you can gather relevant keywords, meta tags, and other SEO elements from HTML pages, helping you improve your own site’s visibility.
What are some effective scraping techniques for beginners?
Effective scraping techniques for beginners include using libraries like Beautiful Soup for HTML parsing, learning to work with APIs, respecting robots.txt for ethical scraping, and starting with simple projects to build your skills gradually. Tutorials and online courses can also provide practical exercises to enhance your learning.
| Key Point | Description |
|---|---|
| Generic HTML Structure | The example provided is a generic landing page for Reuters, lacking specific post content. |
| URL Requirement | A specific article URL or detailed HTML structure is needed for effective scraping. |
| Scraping Guidance | Tools and techniques are available for extracting content from web pages. |
Summary
HTML content scraping techniques are essential for extracting meaningful data from web pages, including news articles like those from Reuters. Despite the generic HTML available for Reuters’ landing page, specific scraping methods can help retrieve substantial content when provided with detailed URLs and structures. By utilizing appropriate tools and programming libraries such as Beautiful Soup, Scrapy, or Puppeteer, one can automate the scraping process, thus obtaining relevant information efficiently while adhering to ethical and legal guidelines.