Vector Databases: A Comprehensive Guide to Unstructured Data
Vector databases are revolutionizing the way we handle and analyze unstructured data. Unlike traditional databases, which excel at managing structured information, vector databases are designed to efficiently index, query, and retrieve high-dimensional vectors, enabling sophisticated similarity searches. One of the key benefits of vector databases lies in their ability to represent complex data such as images, audio files, and text as numerical vectors, making advanced analysis and machine learning tasks much more effective. As businesses increasingly rely on AI and machine learning, understanding what a vector database is and how they work becomes essential in leveraging data for decision-making. From recommendations systems to content understanding, the applications of vector databases are vast and transformative.
Vector databases, also known as similarity search engines or high-dimensional databases, are gaining traction as essential tools in data management. They provide a unique solution to the challenges posed by unstructured data, allowing for enhanced processing and retrieval based on context and relationships. Unlike conventional databases, which focus on structured records, these specialized systems offer a more nuanced approach to understanding data semantics. As organizations explore the many advantages of vector databases, such as improving search capabilities and facilitating AI-driven applications, alternative approaches to data analysis start to surface. This shift toward employing vector-based methodologies signals a new era in how we assess and utilize our ever-expanding datasets.
Understanding Vector Databases: Definition and Fundamentals
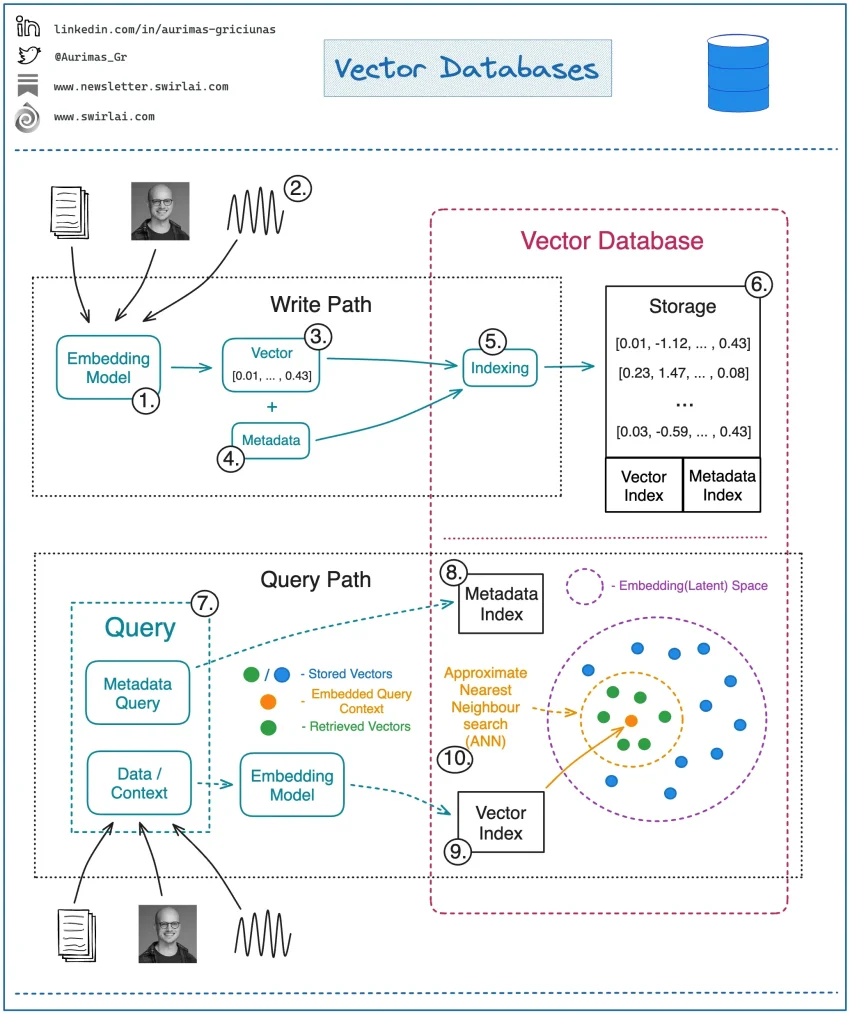
A Vector Database is a specialized data management system designed for the storage and retrieval of high-dimensional vector data. Unlike traditional databases that rely on a structured format, a vector database excels in handling unstructured data by converting it into vectors. This transformation allows for efficient indexing and querying of information based on similarity rather than strict categorization. The ability to represent complex data such as images, audio, and natural language text as vectors opens new avenues for advanced analytics and AI applications, making these databases essential in today’s data-driven landscape.
Vector databases operate using embeddings that capture the essence and relationships of data points within a multi-dimensional space. Each vector consists of unique elements that encapsulate key attributes, allowing for sophisticated data processing methodologies. This capability uniquely positions vector databases to perform similarity searches, where results can be ranked not solely on traditional keyword matching but based on semantic relevance, reflecting a nuanced understanding of user queries.
Benefits of Vector Databases Compared to Traditional Databases
The advantages of using a vector database over a traditional relational or NoSQL database are numerous. First, vector databases are tailored for unstructured data, which is notoriously difficult for traditional databases to manage effectively due to their reliance on predefined schemas. For instance, while a relational database might store a PDF file as a binary object, it cannot interpret the content or meaning within that file. In contrast, a vector database can process the PDF’s textual data, extracting meaningful relationships and allowing for advanced search capabilities that directly enhance user experience.
Moreover, vector databases are optimized for high-performance similarity searches that can handle massive datasets efficiently. Techniques such as HNSW (Hierarchical Navigable Small World) indexing allow for quick retrieval of similar data points, significantly enhancing the speed and accuracy of searches. This high-speed retrieval capability is integral for applications in recommendation systems, content-based image retrieval, and natural language processing, which often require an agile approach to data analysis and interpretation.
The Mechanism Behind How Vector Databases Work
At the heart of vector databases lies the transformation of unstructured data into a numerical format known as vectors. Each vector is a combination of an ID, dimensions, and a payload that together provide a robust representation of the original data. The ID acts as a unique identifier, while the dimensions of the vector capture the essential features of the data, allowing for intricate analysis of context and meaning. This process enables machines to perform complex operations on unstructured data that would be impossible with traditional databases.
Furthermore, distance metrics play a critical role in how vector databases assess the similarity between vectors. Common metrics like Euclidean distance and cosine similarity help determine the proximity of different data points within the vector space. By measuring how close vectors are to one another, a vector database can efficiently return the most relevant search results, making it an invaluable tool for creating personalized user experiences in various applications from e-commerce to social networks.
Applications of Vector Databases in Modern Technology
Vector databases find extensive applications across diverse fields, primarily driven by their ability to handle unstructured data. One prominent example is in the realm of machine learning and AI, where they are utilized for tasks like anomaly detection, sentiment analysis, and image recognition. The inherent capability to represent intricate relationships and semantic meaning allows businesses to develop systems that understand context and provide smarter insights than traditional databases could ever generate.
Additionally, they excel in recommendation engines, a staple for e-commerce platforms, streaming services, and social media. By analyzing user behavior and preferences through vector representations, businesses can deliver highly personalized content, significantly improving consumer engagement and satisfaction rates. As organizations continue to prioritize data-driven strategies, the relevance of vector databases will only increase, paving the way for innovations across various industries.
Vector Database Architecture and Its Components
The architecture of a vector database is composed of essential components that work synergistically to manage vectorized data. Collections are groups of vectors that share similar dimensions and are processed under the same context, facilitating similarity searches within a specific domain. By streamlining the organization of vectors, collections enhance query efficiency and improve response times for data retrieval, making them indispensable for applications with vast data sets.
Moreover, distance metrics are integral to the architecture, guiding how similarity is determined and allowing the system to return accurate and relevant results. Different metrics can be applied based on the application’s needs, whether it be Euclidean distance for straightforward comparisons or cosine similarity for analyzing angles between vectors, thus broadening the functionality and responsiveness of the database.
Choosing the Right Vector Database for Your Project
When selecting a vector database for your project, it is essential to consider factors such as data structure, scalability, and performance requirements. Understanding whether your use case demands high transaction rates or complex analytical queries is critical. For instance, while traditional databases might suffice for structured record-keeping, applications like recommendation systems or natural language processing would benefit significantly from the advantages offered by vector databases.
Additionally, compatibility with existing technologies and systems should be a priority. Many organizations utilize hybrid approaches, integrating both vector and traditional databases to achieve the best results for varied applications. The choice of a vector database also involves evaluating storage options, like RAM-based versus Memmap storage, ensuring that the selected system aligns with your project’s scalability and operational efficiency goals.
Understanding Dense and Sparse Vectors
Vectors in a vector database can be classified into two types: dense and sparse vectors. Dense vectors contain a full set of values representing all features in the data, allowing every element to contribute meaningfully to the vector’s overall interpretation. This is particularly useful in contexts where every bit of data is relevant, such as in image recognition or when analyzing multi-dimensional data.
Conversely, sparse vectors focus only on the most informative attributes, maintaining efficiency by disregarding less relevant data points. In use cases where the majority of the vector’s components might be zero or irrelevant, sparse vectors can significantly reduce memory consumption and enhance processing speeds. Understanding the nuances between these vector types is crucial for optimizing performance in various applications, providing tailored solutions based on specific data characteristics.
The Importance of Indexing in Vector Databases
Indexing is a crucial process that enhances the efficiency of vector databases, allowing them to perform quick searches and manage data retrieval effectively. By creating index structures, vector databases utilize algorithms such as HNSW to arrange vectors in a way that facilitates fast access to similar data points. This method drastically improves the performance of similarity searches, which are inherently more complex than standard keyword-based queries.
Effective indexing also enables vector databases to scale alongside growing data volumes. As your dataset expands, maintaining a responsive search experience becomes paramount, and advanced indexing techniques ensure that queries remain swift and accurate, regardless of the size or dimensionality of the data. Thus, mastering the indexing capabilities within a vector database is vital for success in developing high-performance applications.
Integrating Vector Databases with AI and Machine Learning
The integration of vector databases with AI and machine learning technologies has revolutionized the way data is processed and utilized. By harnessing the power of vector representations, AI models can leverage the rich semantic meaning embedded within the data, allowing for superior analytics, pattern recognition, and automated decision-making. This synergy between vector databases and AI technologies enables businesses to derive actionable insights from complex datasets that traditional systems would find challenging.
Furthermore, machine learning algorithms can enhance the performance of vector databases by continuously optimizing the processes for embedding generation, similarity calculations, and data retrieval. The result is a system that not only improves in efficiency over time but also evolves with the changing landscape of data, making it a vital tool for modern data-driven organizations aiming to stay ahead in innovation and competitiveness.
Frequently Asked Questions
What is a vector database?
A vector database is a specialized system designed to manage high-dimensional vector data efficiently. Unlike traditional databases, which organize data in rows and columns, vector databases facilitate advanced analysis and similarity searches for unstructured data like text, images, and audio, allowing them to be indexed, queried, and retrieved based on context and meaning.
What are the benefits of vector databases?
Vector databases offer significant advantages, such as improved performance for similarity searches, the ability to manage unstructured data effectively, enhanced understanding of data relationships through numerical representation, and the capability to conduct context-based querying. This makes them ideal for applications like recommendation systems and semantic search.
How do vector databases work?
Vector databases function by representing unstructured data as vectors in a multi-dimensional space, enabling advanced similarity searches. Vectors are formed through embedding models that capture the semantic relationships within data. Users can perform operations like indexing, searching, and updating vectors, facilitating complex queries that traditional databases struggle with.
What are common applications of vector databases?
Vector databases are widely used in applications involving unstructured data analysis, such as recommendation systems, semantic search engines, image and audio recognition, and anomaly detection. These databases allow businesses to leverage advanced data insights by retrieving contextually relevant information quickly.
How do vector databases compare to traditional databases?
Vector databases differ from traditional databases primarily in their data structure and querying capabilities. While traditional databases manage structured data using SQL for retrieval tasks, vector databases focus on high-dimensional vectors representing unstructured data, enabling similarity searches based on contextual meaning rather than predefined categories.
| Feature | OLTP Database | OLAP Database | Vector Database |
|---|---|---|---|
| Data Structure | Rows and columns | Rows and columns | Vectors |
| Type of Data | Structured | Structured/Partially Unstructured | Unstructured |
| Query Method | SQL-based (Transactional Queries) | SQL-based (Aggregations, Analytical) | Vector Search (Similarity-Based) |
| Storage Focus | Schema-based, optimized for updates | Schema-based, optimized for reads | Context and Semantics |
| Performance | Optimized for high-volume transactions | Optimized for complex analytical queries | Optimized for unstructured data retrieval |
| Use Cases | Inventory, order processing, CRM | Business intelligence, warehousing | Similarity search, recommendations, RAG |
Summary
Vector Databases allow for advanced analysis and retrieval of unstructured data, which is vital in today’s data-driven world. By understanding the usage, benefits, and architecture of Vector Databases, organizations can effectively harness the power of unstructured data, paving the way for more efficient AI and machine learning applications.
#VectorDatabases #UnstructuredData #DataManagement #AIInfrastructure #TechGuide