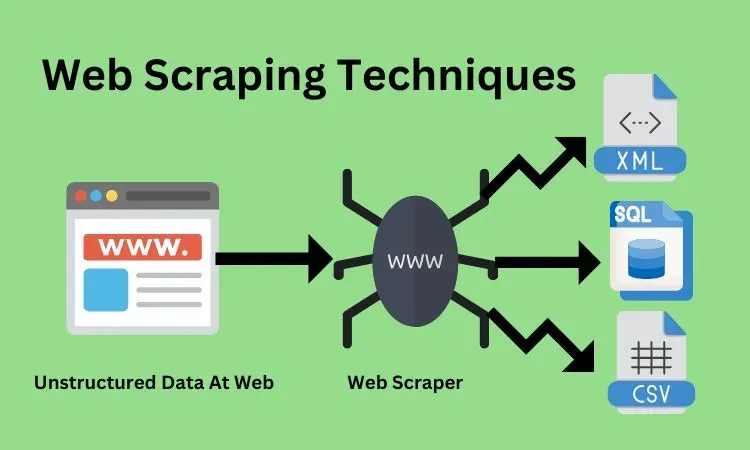
Web scraping techniques are revolutionizing the way businesses collect and analyze data online. By leveraging various methods for data extraction from HTML, users can efficiently gather information from multiple websites, making informed decisions based on real-time data. Whether you’re looking for the best web scraping tools or a comprehensive web scraping guide, understanding how to scrape websites effectively is crucial. This powerful technique not only increases productivity but also opens avenues for competitive analysis and market research. With the right skills, anyone can master HTML data extraction and unlock a treasure trove of information available on the internet.
In the realm of data mining and web data extraction, various methods allow individuals and businesses to harvest valuable information from the vast landscape of the web. These practices, often referred to as automated data collection or online data harvesting, enable users to systematically retrieve and organize data from different online sources. By delving into web crawling and API utilization, one can discover new insights and trends from the digital ecosystem. The strategies employed for these purposes require understanding the basics of HTML structures and leveraging tools designed for efficient extraction. As the digital world expands, mastering these techniques becomes essential for anyone aiming to stay ahead in a data-driven environment.
Understanding Web Scraping Techniques
Web scraping is an essential skill for data analysts and researchers aiming to gather information from online sources. Knowing various web scraping techniques can significantly enhance your ability to extract relevant data efficiently. Typical methods include using libraries like Beautiful Soup in Python for parsing HTML documents, which enable you to navigate through the web’s data structures effortlessly. By understanding how to scrape websites, you can automate the data gathering process, saving time and resources while acquiring a wealth of information.
Furthermore, it’s critical to approach web scraping responsibly, adhering to the ethical guidelines and terms of service of the websites you target. This ensures that your data extraction remains compliant and does not disrupt the functionality or availability of the site. Familiarity with web scraping tools such as Scrapy and Selenium can further aid in executing complex scraping tasks. These tools allow you to manage requests, handle cookies, and even scrape websites that employ JavaScript to load content dynamically.
A Comprehensive Web Scraping Guide
A comprehensive web scraping guide should start with defining the objectives of your project. Are you looking to collect data for analysis, monitor price changes, or compile articles? Each goal may require a different approach to data extraction from HTML. After you establish your goals, you can choose the appropriate web scraping tools and techniques that best fit your needs. Detailed planning at this stage can significantly influence the efficiency and success of your scraping efforts.
In your web scraping guide, it’s also vital to discuss the best practices for effective HTML data extraction. For instance, ensuring your scraper respects the robots.txt file of a website is crucial to maintain ethical scraping practices. Additionally, implementing delay mechanisms between requests can prevent overwhelming the server with too many simultaneous requests, reducing the risk of being banned. By following these guidelines, you can enhance your web scraping projects while effectively gathering quality data.
Essential Tools for Data Extraction from HTML
While numerous tools exist for data extraction from HTML, several have emerged as industry favorites. Libraries like Beautiful Soup and lxml specialize in parsing HTML documents, making it easy to locate and extract the required data elements. In contrast, Scrapy provides a more robust framework that is ideal for larger projects, offering features such as data storage and pipeline management. The choice of tool often depends on the complexity of the data you intend to scrape and your familiarity with programming languages.
Moreover, browser automation tools like Puppeteer and Selenium are invaluable for scraping websites that dynamically alter content based on user interaction. These tools can simulate browser actions such as clicking buttons or scrolling through pages, thus allowing you to obtain data that is difficult to access through static HTML structures. As such, a good understanding of the available web scraping tools and their specific use cases can greatly enhance your data extraction workflows.
Best Practices for Ethical Web Scraping
Ethical web scraping is paramount in today’s data-driven environment. Practicing good etiquette involves respecting the target website’s terms of service, understanding their data use policies, and complying with requests to limit scraping. Always check the robots.txt file of a website to determine what data you are allowed to scrape. Also, being transparent with your intent and method can avoid potential conflicts with website owners.
Another best practice includes implementing responsible crawling strategies, such as rate limiting your requests or using randomized delays. This behavior mimics human interactions with the site and minimizes disruption to the server’s performance, protecting both the site’s integrity and your scraping efforts. By adhering to these best practices, you can ensure your web scraping endeavors are responsible and sustainable.
Understanding HTML Data Structure for Effective Scraping
To effectively scrape data from websites, it is crucial to understand the HTML data structure. HTML documents are built using nested elements that define how content is organized on a webpage. By familiarizing yourself with tags like
,
,
, and others, you can strategically use web scraping tools to target and extract the specific information you need. Navigating through this structure is key to ensuring your scraping process yields accurate results.
Moreover, recognizing attributes such as class and ID within HTML elements can help in precisely locating the data of interest during extraction. This understanding not only facilitates better scraping practices but also helps avoid capturing unwanted data. Understanding the intricacies of HTML structure will greatly improve your efficiency and accuracy in data extraction efforts.
Utilizing Python for Web Scraping Projects
Python has emerged as one of the preferred programming languages for web scraping due to its simplicity and the powerful libraries available. Libraries such as Beautiful Soup, Scrapy, and Requests provide profound capabilities for navigating and extracting data quickly. By learning how to scrape websites using these libraries, you can automate routine data collection tasks and focus on analyzing the data rather than gathering it.
Furthermore, Python’s extensive community support means you can find numerous tutorials, forums, and documentation to assist you in troubleshooting and expanding your scraping projects. As you gain proficiency in using Python for web scraping, you’ll unlock the potential to handle more complex extraction tasks, such as multi-threaded scraping or scraping content across multiple domains seamlessly.
Challenges in Web Scraping and How to Overcome Them
Web scraping can pose various challenges, including handling dynamic content, websites employing anti-scraping techniques, and the constant changes in web layouts. When scraping websites that employ JavaScript to load their content dynamically, traditional scraping methods might fall short, prompting users to explore alternatives like headless browsers or Puppeteer. Understanding how to use these technologies can allow you to effectively extract the data hidden within JavaScript operations.
Additionally, many websites implement measures against scraping, such as CAPTCHAs or IP blocking. To overcome these obstacles, implement techniques like using rotating proxies or CAPTCHA-solving services to maintain your scraping capabilities without triggering security alarms. Continuous adaptation to the changing landscape of web technologies is essential for successful web scraping operations.
Legal Considerations in Web Scraping
As the popularity of web scraping grows, so does the scrutiny surrounding its legal implications. Understanding the legal considerations surrounding data extraction is vital. Many websites explicitly outline their terms of service, which may include prohibitions against scraping their content. Violating these terms could lead to legal repercussions or bans from accessing the service.
Additionally, one must also consider data ownership laws and copyright regulations. Your scraping endeavor might inadvertently violate copyright protections if you are not careful about the nature of the content collected. Therefore, it’s prudent to remain informed about data protection laws and consult with legal professionals when necessary to ensure compliance and protect yourself from potential liabilities.
Future Trends in Web Scraping
The landscape of web scraping is continuously evolving, influenced significantly by advancements in technology and changing regulations. As AI and machine learning technologies become more integrated into data processing tasks, we can expect enhanced web scraping tools capable of intelligent data extraction. Such tools may automatically adapt to layout changes or dynamically interact with content without manual input.
Moreover, increased emphasis on data privacy is likely to shape the future of web scraping. With stricter regulations being implemented worldwide, scraping practices will need to evolve to ensure that they comply with laws governing personal data and privacy. Staying ahead of these trends will be crucial for anyone involved in data extraction in order to maintain ethical and effective scraping practices.
Frequently Asked Questions
What are the most popular web scraping tools for data extraction from HTML?
There are several powerful web scraping tools available for data extraction from HTML, including Beautiful Soup, Scrapy, and Selenium. Each of these tools has unique features that facilitate web scraping, such as parsing HTML, handling JavaScript, and managing requests.
How can I learn how to scrape websites effectively?
To learn how to scrape websites effectively, start with a web scraping guide that covers the basics of HTML data extraction techniques. Familiarize yourself with libraries like Beautiful Soup or Scrapy and practice by scraping simple websites to build your skills.
What is the best approach to HTML data extraction using Python?
The best approach to HTML data extraction using Python involves using libraries like Beautiful Soup or lxml in conjunction with requests. This combination allows you to make HTTP requests, parse the HTML response, and easily extract the data you need.
What are the legal considerations for web scraping techniques?
When using web scraping techniques, it’s important to adhere to the website’s ‘robots.txt’ file and terms of service. Always ensure that your data extraction does not violate copyright laws or any applicable regulations.
Can web scraping tools handle dynamic content?
Yes, many web scraping tools can handle dynamic content. For example, Selenium is commonly used for scraping websites that rely on JavaScript, as it can automate a web browser to load and render the page before extraction.
What are some challenges associated with data extraction from HTML?
Challenges associated with data extraction from HTML include dealing with websites that frequently change their structure, handling JavaScript-rendered content, and ensuring compliance with legal restrictions on data usage.
How can I automate data extraction from HTML using web scraping?
To automate data extraction from HTML, you can write scripts using web scraping frameworks like Scrapy or use tools like Puppeteer. These allow you to schedule scrapers and collect data at regular intervals without manual intervention.
Is it possible to scrape multiple websites simultaneously?
Yes, you can scrape multiple websites simultaneously by using asynchronous programming in Python or utilizing web scraping tools that support concurrent requests, such as Scrapy, which can manage multiple threads.
What is a web scraping guide and why is it useful?
A web scraping guide is a resource that provides step-by-step instructions on how to effectively use web scraping tools and techniques. It is useful for beginners to understand the fundamentals of data extraction from HTML and avoid common pitfalls.
How do I ensure accurate data extraction when scraping websites?
To ensure accurate data extraction when scraping websites, validate the extracted data against expected formats, manage error handling in your code, and regularly update your scraping logic to accommodate changes in the website structure.
| Key Aspect |
Details |
| AI Limitations |
The AI cannot directly scrape the web or access live data. |
| Data Extraction |
AI can provide guidance on extracting data from HTML. |
| User Interaction |
Users can input specific HTML content for analysis. |
Summary
Web scraping techniques are essential for data extraction from websites. In today’s digital world, the ability to gather and analyze data efficiently from various online sources is crucial for businesses and researchers alike. Understanding how web scraping techniques function allows users to automate data collection, leading to more informed decisions. Whether you’re a novice or a professional, familiarizing yourself with the nuances of web scraping can significantly enhance your data analysis skills.